Table of Contents
Topic Statement
This project had the wonderfully original goal of creating a sort of calculator capable of performing addition, subtraction, and multiplication with a workable subset of the rationale numbers (termed “floating point numbers”) while attempting to make optimizations to make the computation reasonably fast. Our unit is designed so that it can be attached to other modules and used within other designs and was inspired by the the age of floating point coprocessors that could be bought separately and attached to home computers.
Significance
Although floating point calculation was touched upon in our class when we discussed representing numbers, all labs and homeworks involved strictly integer calculation. Knowing that floating point representations introduced multiple complications not present in integer or fixed point arithmetic, we wanted to investigate the process for representing and doing computation with floating point numbers. While the procedures for addition, subtraction, and multiplication are well known to humans, we often take for granted what steps these operations involve. For instance, when adding or subtracting with decimals, we automatically known how to align our digits so that the decimal point is correctly placed. When multiplying 5 * 3, we don't add 5 three times; instead, we likely have our multiplication tables up to 10*10 (probably even higher) memorized. Ideally, those reading this document will appreciate the complexity of the most basic arithmetic, long forgotten in the era of elementary school. Surprisingly, our implementation of addition, subtraction, and multiplication in the computer is quite human!
Method
Representation
The first and probably most important design decision we made was on our representation. There are many ways to represent rationale numbers and each has its own tradeoffs to be made.
- “IQ” notation. This representation tells us exactly how many bits are before and after the radix. This is obviously not what we wanted because it is by definition fixed point!
- IEEE 754 is a standard that all modern computers understand that uses a sign bit, exponent, and fraction to represent a number.It is designed to have no redundancy and be very space efficient. Unfortunately, it is quite awkward to do arithmetic with.
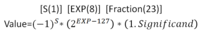
- Scientific notation includes an exponent and a fraction. It's pretty convenient to do computations with. Addition requires normalizing exponents and then adding the fraction while multiplication requires multiplying the fractions and adding the exponents. It's perfect! But…it's in base ten.
- Scientific notation in base two is a reasonably simple representation we eventually ended up using. All exponents and fraction sections are signed. This representation is quite inefficient as there are many ways to represent the same value, but it is convenient to work with, especially on our time scale.
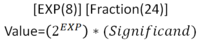


Hierarchical Block Diagram
All modules are designed, simulated, and tested in Modelsim PE and are written in Verilog.
Complete FPU
This is the top level module. It just hooks up the adder/subtractor and multiplier, plus deals with bus size discrepancies and flow control.

Addition/Subtraction
Addition would be as simple as it sounds if there was no exponent to deal with. Before operands enter our adder, they must first be normalized to the larger of the two exponents. We do this by finding the difference of exponents, and shifting the smaller operand by the difference. This process is vulnerable to losing precision, especially if one exponent is much larger than the other. The larger exponent is passed out to the result, and the shifted operands are then added as usual. Subtraction is identical as negatives are dealt with nicely in two's complement notation. Normalizing to the exponent in subtraction is the same as in addition.
Multiplication
Multiplication starts with making sure both operands are positive and the reset flag is pulsed. If they're negative, they aren't anymore! The two's complement representation of a negative number was troublesome to deal with, so we removed it and dealt with it at the end by looking at the signs of the inputs. That said, multiplication with a computer is surprisingly human, behaving similarly to long multiplication from 3rd grade. To try this method yourself, write down operand A and operand B. If the rightmost place of B is 1, add the value of A to an accumulator. Then, shift A to the left 1 place, filling in the empty place with a zero, and shift B right one place, again filling in the empty with a zero. Repeat the cycle of adding A is the rightmost place of B is 1 until all places of B are zero. After this shift and accumulate process is done, we change the sign of the output to match the inputs. The multiplier will display its result as soon as it is ready (it sees that B is all 0). To find the correct exponent in a multiplication operation, just add the input exponents. If the exponents cause an exception by having a carryout or overflow, an output flag will indicate that the exponent displayed is not valid. The res_ok flag in multiplier's internals becomes true when the B operand is entirely shifted out, signalling that the operation is finished. This flag allows the result to be displayed early if B is short! 
Carry Select Adder
The carry select adder is a special type of adder that resolves more quickly than a ripple adder. It saves time at the cost of additional hardware by calculating the result of smaller groups of a larger bit both with and without a carry in. When the carry in of the previous group is known, a mux selects whether the value with or without carry in makes it to the output. While a ripple adder takes (adders)*(time per adder) to complete, the carry select adder takes (adders in group)*(time per adder)+(number of muxes)*(time per mux). By choosing the correct group size, the carry select adder can beat a ripple adder by performing all adds in parallel and only selecting muxes (which are pretty damn fast) serially. By counting how many NAND gates the longest signal needs to flow through in both our mux and adder, we determined that we could make the fastest 64-bit adder with 8 groups of 8 adders.
 The above diagram is a single block block with a group size of four. Making the full adder involves producing more of those blocks and stringing the carryouts to carryins.
The above diagram is a single block block with a group size of four. Making the full adder involves producing more of those blocks and stringing the carryouts to carryins.
Multiply by -1
As it turns out, multiplication is a lot easier with unsigned numbers than signed numbers. To get around this, we included a unit that will multiply by -1 (it just reverses the 2's complement) if an input to our multiplier comes in negative. The output is then adjusted accordingly if it must be negative. This approach requires more adders but does not cause a terrible speed penalty as the two more adders' time only increases the number of add transactions in the multiply op by 6.25%
Other (Modules created with behavorial constructs.)
- Barrel Shifter - Shifts an input in either direction by a specified amount. Unique because it can shift several places simultaneously.
- 1-bit Full Adder - Adds two single bits and has a carry in and carry out. It is building block for our entire design.
- Mux - Selects an input and maps to an output.
- Set on Less Than - Will emit true if operand a is less than operand b.
- Sign Extension - Used to make smaller numbers go into bigger ports. Just sticks a bunch of 0's on the left of a positive number, or 1's on a negative number.
- Register - Holds data until new data comes in on the next clock cycle.
- Up Counter - Increments a value by 1 every clock cycle until a certain value is reached. Our up counter must be reset at the start of every multiply operation.
Try it Yourself, Or Expand On It!
All necessary files are included in “FPU.zip” To run or build on this project, only some knowledge of Verilog is required. The HDL simulator Modelsim was used for developing the system, but any Verilog simulator should do, pending modification of our do files. We assume the user has some Verilog simulator installed and thus do not provide installation instructions. There are no build instructions because there is no hardware.
Module Organization Scheme & Run Directions
Module table index.
adder.v
- f_adder(out, carryout, a, b, carryin);
- workgroup8(output[7:0] out, output carryout, input[7:0] opA, input[7:0] opB, input carryin, output overflow);
- csa64(output[63:0] out, output carryout, input[63:0] opA, input[63:0] opB, input carryin);
- csa24(output[23:0] out, output carryout, input[23:0] opA, input[23:0] opB, input carryin);
- csa32(output[31:0] out, output carryout, input[31:0] opA, input[31:0] opB, input carryin, output overflow);
complete_add.v
- bitshift_right(input[23:0] opA, input[7:0] shift, output[23:0] shifted_opA);
- bitshift_left(input[23:0] opA, input[7:0] shift, output[23:0] shifted_opA);
- sign_extend_8_to_32(input[7:0] operand, output[31:0] res);
- sign_extend_24_to_32(input[23:0] operand, output[31:0] res);
- sign_extend_32_to_56(input[31:0] operand, output[55:0] res);
- complete_add(input[31:0] opA, input[31:0] opB, input carryin, output[31:0] res, output final_carryout, output final_overflow);
multiply.v
- negate_32(input negate, input[31:0] operand, output[31:0] res);
- negate_64(input negate, input[63:0] operand, output[63:0] res);
- multiplier(input clk, input reset, input[31:0] opA, input[31:0] opB, output[63:0] res, output res_ok);
- complete_multiplier(input clk, input[31:0] opA, input[31:0] opB, input reset, output exp_ok, output[55:0] result);
SLT.v
- SLT_behavioral(input[31:0] input1, input[31:0] input2, output res);
- SLT_structural(input[31:0] opA, input[31:0] opB, output res);
- inverter_32(input[31:0] operand, output[31:0] res);
support_modules.v
- barrel_shifter32(input[4:0] shamt, input dir, input[31:0] dataIn, output[31:0] dataOut);
- barrel_shifter64(input[4:0] shamt, input dir, input[63:0] dataIn, output[63:0] dataOut);
- sign_extend_u(input[31:0] operand, output[63:0] out);
- sign_extend_s(input[31:0] operand, output[63:0] out);
- upcounter(input clk, input reset, output reg[4:0] cval);
- adder64(input[63:0] opA, input [63:0] opB, output[63:0] res);
- reg64(input clk, input[63:0] dataIn, output reg[63:0] dataOut, input reset);
- and64(input[63:0] dataIn, input compare, output[63:0] dataOut);
- mux2_1_1(input in0,input in1,input sel,output out);
- mux2_1_1s(input in0,input in1,input sel,output out);
- mux2_1_32(input[31:0] in0,input[31:0] in1,input sel,output[31:0] out);
- mux2_1_64(input[63:0] in0,input[63:0] in1,input sel,output[63:0] out);
- mux3_1_1(input in0, input in1, input in2, input sel, output out);
- mux3_1_56(input[55:0] in0, input[55:0] in1, input[55:0] in2, input[1:0] sel, output[55:0] out);
- mux3_1_2(input[1:0] in0, input[1:0] in1, input[1:0] in2, input[1:0] sel, output[1:0] out);
Run Pre-built Test
- test_fpu.do - Runs tests that involve the entire unit. Test cases are fed in manually as this unit has no flow control of its own.
Download the things here.fpu.zip
Work Plan
Our original work schedule was very functional and we had an adequate amount of time to finish the modules that we hoped to finish. Specifically, we had spent about 8 hours per week working on the project. We only spent a bit more time when we were merging the modules together and creating the top-level module.
The Unexpected
Here's a list and description of problems, tradeoffs, or frustrations that weren't immediately obvious when we made our initial design.
- Our multiplier design is clocked, but the adder/subtractor isn't. This raised an interesting question of whether to allow a clock input from external hardware, or to include an internal clock as some commercial floating point processors did. Ultimately, we decided to use an external clock for simplicity, but a case can be made for the alternative. Since the FPU has the potential to be clocked faster than the rest of the CPU due to having fewer total components, having an internal clock should yield better performance.
- Our representation made a huge tradeoff in precision when adding numbers with vastly different exponents. When one exponent is much bigger than the other, shifting the smaller operand will likely lose some or even all data bits. To prevent this, some foresight and adjustment of input operands will be required.
- The counter in our multiplication unit that keeps track of how many places operands have been shifted needs to be reset whenever a new operation comes in. We could not think of a way to reset automatically as the obvious choices, to reset when the operation or operand changes, will not work if the same operation with the same operands is requested twice in a row. Instead of using a barrel shifter than shifts the number of places the up counter says to, a single bit shifter could be used to shift one place each cycle, then keep the result in a register. This alternative would still require some sort of control of said register, namely providing a write enable.
- Representing exponents and fraction sections in 2's complement actually ended up being easier than trying to keep track of the sign bit separately like in IEEE 754. This was somewhat unexpected as we expected dealing with only unsigned numbers to be easier. Unsigned numbers are nice until we need to subtract. The only notable frustration with signed numbers is that they confuse the multiplier, but this was easily dealt with by inverting, then adjusting the inputs and outputs to the multiplier.
- Since the result of a multiplication requires twice as many bits as its inputs, our multiplier outputs an awkward 56 bit result (8 exponent, 24*2 fraction). Without the time to make a truncator, which introduces its own design challenges, this 56 bit answer is non-standard.
Make it Better
Here's a grocery list of features or optimizations we really wanted but didn't have time (or wits…) to implement. The coolest ones are bolded.
- Maximize component reuse. For instance, this design has a billion adders all over the place and we can't help but think lots of them can be reused. Multiply and Add/Subtract never need to be valid at the same time; we wish we had the time to attempt to repurpose some of those parts.
- Add timings to code, and profile different configurations. Although we tried to make faster modules when possible, it can be done better. We like to think that our carry select adder's 8 by 8 configuration was a good choice, but it's possible that with more analysis than scribbling on the back of our tuition statements, a more optimal configuration can be found, especially since the groups in the adder don't need to be the same size at all. Also, while the carry select adder beats the ripple adder, isn't the fastest or smallest thing alive. Could a lookahead adder beat it perhaps?
- Come up with a better 32bit representation. Our scientific notation-esque representation is easy to work with, but wildly inefficient. IEEE 754 is very efficient in size but annoying to work with and not really for doing math on. Surely there is a better compromise.
- Be IEEE 754 compliant, at least at the inputs and outputs.
- Do more ops. How about division? That's the same thing as multiplication by a reciprocal! But how do we get the reciprocal? Is that even how this works?
- Find a way to hook it up to the CPU lab's deliverable and then have floating point op codes that involve the coprocessor. Make the CPU lab more fun.
- Add some additional capabilities. A couple of yellow(difficult, but maybe) features from our work plan included performing round, floor, or ceiling functions on the output, truncating the now 56bit output to 32 bits, and even trying to provide some kind of error estimation.
- Add additional logic that tries to create the highest precision representation. When designing our add function, we noticed that any leading zeros on the operand with the bigger exponent are essentially lost precision if they cause precision bits to be shifted out of the smaller operand. We wish we could adjust the bigger operand first to allow the smaller operand more room for precision bits. Since there are multiple representations of each number in our encoding, this could be achieved by moving the bigger operand as far to the left as possible and then adjusting its exponent accordingly.
- Synthesize it and flash it to the FPGA. Then, overclock and apply liquid nitrogen. Actually don't.